EQ in Robots
Asessing team dynamics in realtime conversation
I worked on this project over the summer of 2021 with the Human-Robot-Interaction Lab under Sarah Sebo in collaboration with the UChicago Center for Data and Computing.
In this project we attempted to predict how included and psychologically safe members of a conversation felt, by analyzing video and audio data.
Technologies used
This project utilized common data-analysis and processing tools in Python, including Pandas Scikit-Learn, as well as computer vision (and hearing) tools such as OpenCV, OpenFace and openSMILE.
We built our machine learning models using Keras and Tensorflow
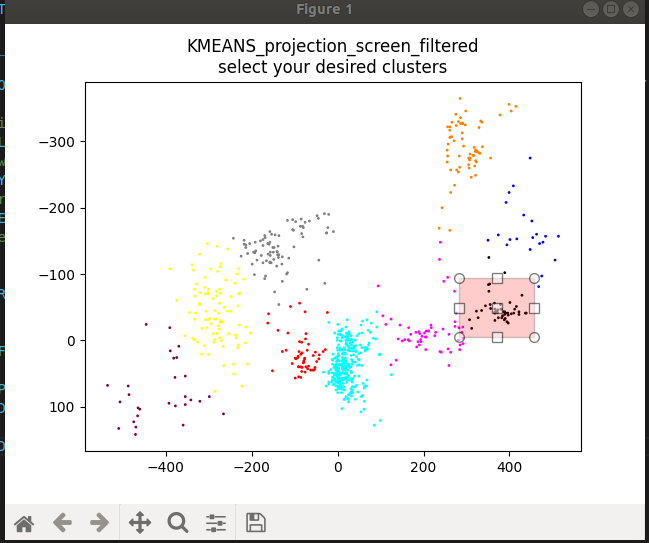
Tools built
In the process of developing the models we built an interactive gaze-classifier ,that would classify detected gazes according to direction. We could cluster them to determine potential points of interest and select custom ranges when we knew where points of interest where. For debugging you could select custom ranges and clusters, the videos of the selected ranges would then play. This helped deciding on whether the clusters and selections where performing as expected.
We trained both an RNN and a regular DNN for analyzing the data, guessing the inclusion and psychological safety scores of conversation members, as well as predicting who of the team members felt least included. Then, we built a selection of tools that would visualize model performance using matplotlib and set up a pipeline to extract low-level features from the video and audio using OpenCV, OpenFace and openSMILE. These low-level features where then piped through an intermittent layer of processing to extract higher level features from the low-level features and format them for training.
See the video above to check out a summary of the surrounding research and the results of our study.
While the practical application of the models is limited at this stage, they did reveal an interesting bias within our research group. We were terrible at identifying the least included person by hand, worse than if we had guessed at random. Instead, we discovered that we tended to judge people based on the amount of participation in the conversation, but we did not catch on people who where content in being quiet, or tried masking their discomfort by participating loudly. Exploring why we have these biases, and to what extent they are observable in the population and what potential influences that might have on our interactions are exciting avenues of future work. In an interdisciplinary setting, projects like this might be able to continue in unexpected directions, if the observations and discoveries call for it.
Collaborators: Jason Lin, Javier Portet, Stephanie Kim.
Mentor: Sarah Sebo